
มาสร้างไฟล์ Cascade ไว้ใช้ตรวจจับวัตถุกัน
ในตอนที่แล้วนั้น ได้แสดงตัวอย่างการเขียนโปรแกรม Face Detection โดยใช้ Library SimpleCV บนภาษา Python ที่มีข้อดีคือ ใช้งานง่าย ไม่ยุ่งยาก โดยในตอนนั้นเราจะเห็นว่า มีไฟล์ xml ชื่อ face.xml ที่ถูกใช้ในฟังก์ชัน findHaarFeature และในตอนนี้เราจะมาทำความรู้จักกับ Haar feature-based ซึ่งถูกพัฒนาขึ้นมาเพื่อใช้ในการตรวจจับวัตถุ และเราจะมาสร้างไฟล์ xml ของเราเองกันครับ
แต่เดิมกระบวนการตรวจจับวัตถุ หรือแยกแยะวัตถุนั้น เป็นกระบวนการที่ใช้พลังงาน และทรัพยากรสูงมาก แต่เราจะมาทำความรู้จักกับหนึ่งในรูปแบบของกระบวนการ Haar feature-based ที่ถูกพัฒนาเพื่อให้สามารถทำงานได้อย่างรวดเร็วมากขึ้น โดยวิธีนี้ถูกนำเสนอเมื่อปี 2001 โดย Paul Viola และ Michael Jones ได้ตีพิมพ์ผลงานของพวกเขาในหัวข้อ “Rapid Object Detection using a Boosted Cascade of Simple Features” ซึ่งใช้กระบวนการ Machine Learning ตามที่ฟังก์ชันคาสเคดได้ถูกสอนผ่านการวิเคราะห์รูป ซึ่งถูกแบ่งเป็นสองกลุ่มคือ กลุ่มรูปถูกต้อง ซึ่งคือรูปของสิ่งที่เราอยากจะตรวจจับ ในรูปแบบต่างๆ แต่ต้องมีการตัดเอาส่วนอื่นออก ให้เหลือเพียงส่วนของสิ่งที่เราต้องการเท่านั้น และกลุ่มของรูปทั่วไป ที่ไม่มีสิ่งที่เราอยากจะตรวจจับอยู่ในรูปเลย เพื่อที่จะสามารถนำข้อมูลที่ได้ไปตรวจจับ ในรูปอื่นๆต่อไป
วิธีที่ Paul Viola และ Michael Jones คิดค้นขึ้นมาใช้นั้น ช่วยให้ลดการใช้ทรัพยากร และเวลาในการประมวลลงได้อย่างมาก โดยพวกเขาเรียกว่า “Fast computation of Haar-like features” วิธีคือ การแบ่งพื้นที่ของภาพด้วยรูปแบบสำเร็จรูป 4 แบบที่พวกเขาได้กำหนดจาก Haar-like features ไว้ดังรูป ( A – B – C – D ) จากนั้นจึงคำนวณตารางสีของภาพโดยการ อินทิเกรตตารางสีที่อยู่ในพื้นที่อยู่ในช่องสีขาว ลบด้วยตารางสีที่อยู่ในพื้นที่อยู่ในช่องสีดำ ในกระบวนการสร้าง รูปอินทิกรัล แล้วนำผลที่ได้ไปใช้ใน Adaboost ที่เป็นอัลกอริทึมสำหรับการเรียนรู้แบบหนึ่ง ( Adaptive Boost Learning Algorithm ) เนื่องจากจำนวนข้อมูลมีจำนวนมหาศาล ( ขนาด 24 x 24 ช่อง จะมีรูปแบบที่เป็นได้ทั้งหมด 162,336 รูปแบบ ) การเลือกใช้ Adaboost จึงเป็นทางออกที่ดี และเหมาะสมที่สุด ( ปล. เรื่อง Adaboost ยังไม่ได้อ่านอย่างละเอียดครับ และไม่มีความเชี่ยวชาญเลย ดังนั้นข้อมูลทั้งหมดตรงนี้ ผมแปลเอาครับ ) และใช้ Cascading Classifiers ในการทำให้ระบบเรียนรู้ผ่าน ตัวอย่างข้อมูลที่ถูกต้องจำนวนหนึ่ง และข้อมูลที่ไม่เกี่ยวข้องอีกจำนวนหนึ่ง เพื่อให้ระบบสามารถเรียนรู้ความแตกต่างได้ครับ
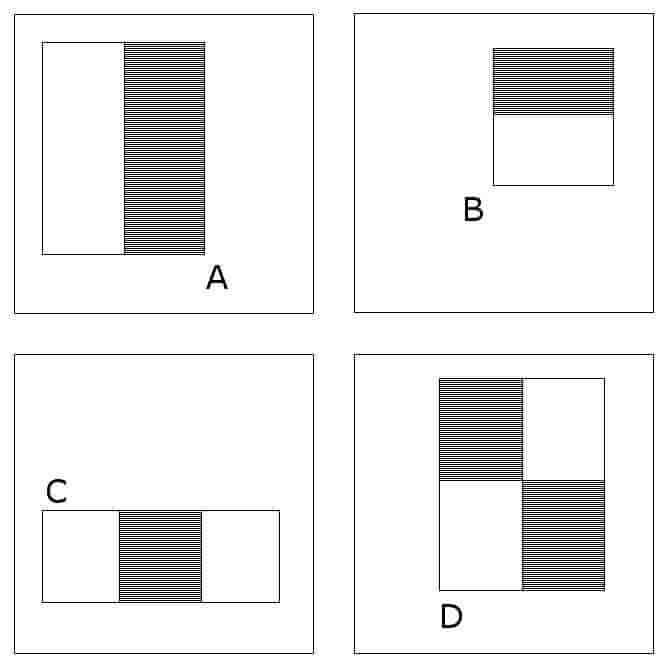
รูปแบบ Haar Like Feature 4 แบบที่ถูกเลือกใช้
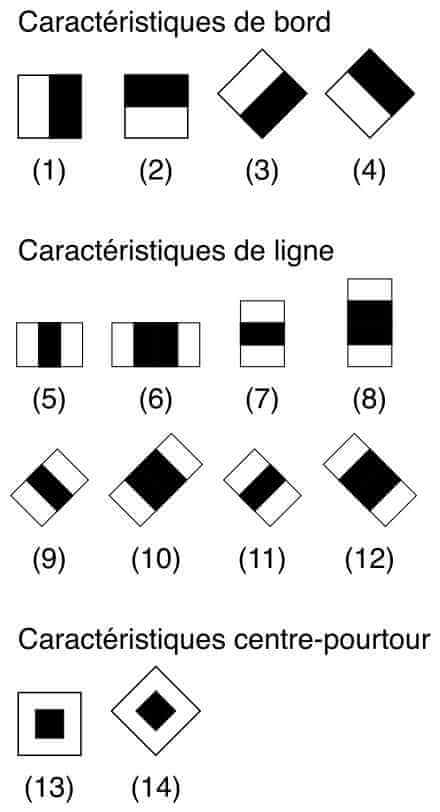
รูปแบบเพิ่มเติมที่ถูกพัฒนาโดย Rainer Lienhart and Jochen Maydt
ทีนี้เราจะมาลองสร้างไฟล์ cascade ที่เป็น xml สำหรับใช้ในการตรวจจับวัตถุ จากกระบวนการ Haar Cascade Training กันครับ
ขั้นตอนแรกคือ เตรียมไลบรารี่ และข้อมูล ต่างๆ
เราจะต้องติดตั้ง OpenCV และ Library ต่างๆที่จำเป็น
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev libopencv-dev
และเราต้องการใช้รูปอีกจำนวนมาก โดยแบ่งรูปออกเป็น สองกลุ่ม
กลุ่มแรก คือ รูปเฉพาะของสิ่งที่เราต้องการจะตรวจจับ โดยเราจะเรียกรูปเหล่านี้ว่า “รูปของสิ่งที่เราสนใจ” ในที่นี้เราจะเก็บมันไว้ในโฟลเดอร์ pos
กลุ่มที่สองคือ รูปที่ไม่มีสิ่งที่เราต้องการจะตรวจจับ และควรจะเป็นรูปทั่วๆไป ไม่ใช่รูปเฉพาะของสิ่งของใดครับ
และเราจะเรียกรูปกลุ่มนี้ว่า “รูปของสิ่งที่ไม่เกี่ยวข้อง”
การหารูปของสิ่งที่เราต้องการจะตรวจจับ จำนวนมากๆ ไม่ใช่เรื่องง่าย
ผมเลือกที่จะดาวน์โหลดจากเว็บนี้ http://image-net.org/ ซึ่งไปเจอในตัวอย่างการทำ Cascade File มาครับ โดยเว็บนี้จะรวบรวมรูปภาพต่างๆไว้เป็นจำนวนมากในรูปแบบ url และมีการแบ่งหมวดหมู่ไว้ค่อนข้างดีทีเดียว ทำให้สะดวกมากถ้าต้องการรูปอะไรสักอย่างจำนวนมากๆ
การเตรียมภาพ ที่จะใช้เป็นข้อมูล
รูปที่ผมสนใจคือ รูปเครื่องบินรบ ครับ นั่นคือสิ่งที่จะใช้ทดลองในตัวอย่างนี้ โดยการค้นหาด้วยคำว่า “Aircraft”

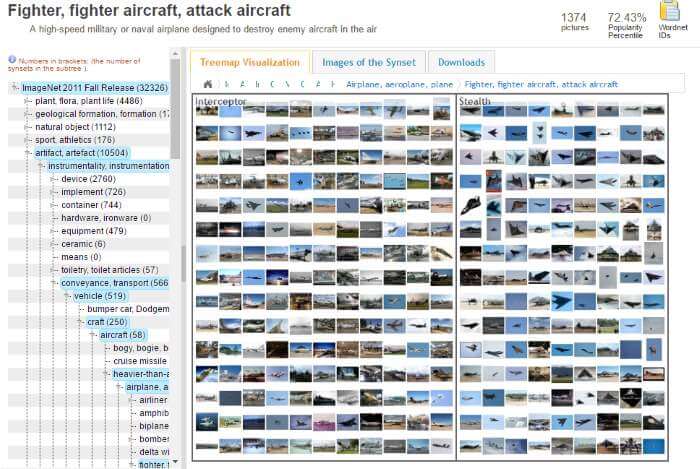
ซึ่งหน้าต่างทางซ้ายนั้นเราสามารถเลือกประเภทที่เฉพาะเจาะจงเข้าไปอีกได้ หรือจะเลือกจากกลุ่มภาพตัวอย่างที่มีให้ดูก็ได้
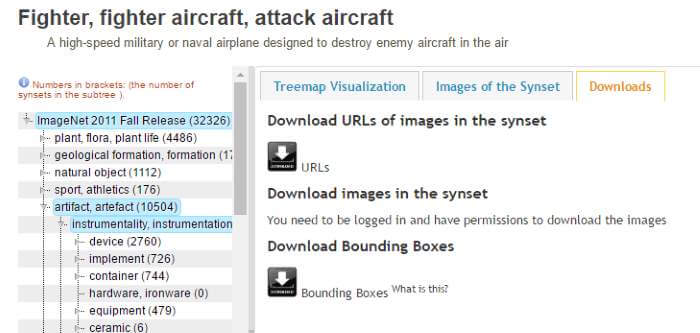
เมื่อผมเลือกชุดของรูปเครื่องบินที่ผมต้องการได้แล้ว ในเว็บนี้เราสามารถดาวน์โหลดรูปได้จาก url โดยการเลือกที่ แถบ Download ขางบนก็จะปรากฏดังภาพ
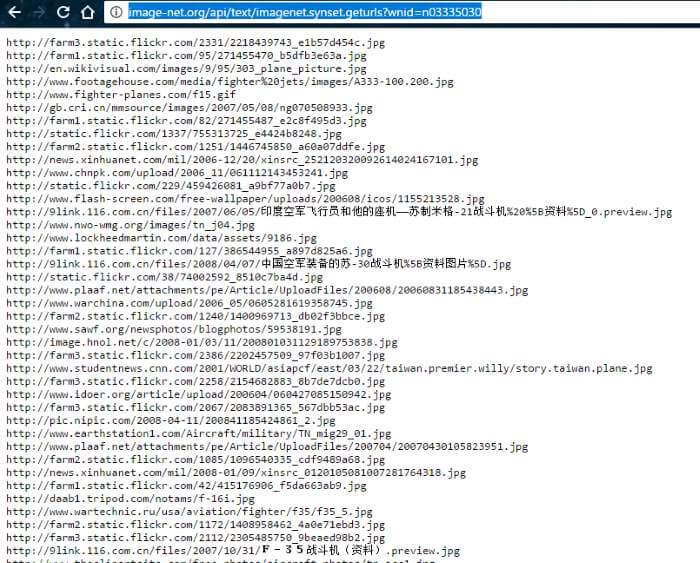
ให้เราคัดลอก URLs ข้างบนไว้ เพราะเราจะโหลดรูปโดยใช้ URLs นี้ ไปเก็บไว้ใน โฟลเดอร์ pos ครับ
ต่อมาให้เราหาภาพวิวที่คิดว่าจะไม่มีสิ่งที่เราสนใจจะตรวจจับไปปรากฏในนั้น ผมเลือกที่จะใช้ภาพสนามบิน และท่าอากาศยาน ไปเก็บไว้ใน โฟลเดอร์ neg ( ซึ่งการเลือกท่าอากาศยานนั้นไม่ใช่ความคิดที่ดีแน่ๆครับ แต่อยากลองว่าถ้าภาพใกล้ๆกันมันยังทำงานได้รึเปล่าครับ แนะนำว่าควรใช้ภาพแนวอื่น เพื่อสิ่งที่ดีกว่านะครับ ) และผมก็ได้ URLs นี้มา http://image-net.org/api/text/imagenet.synset.geturls?wnid=n02692232
เริ่มต้นโหลดภาพ
ภาพที่เราจะใช้ในการสร้างไฟล์ Cascade ครั้งนี้ เราจะต้องทำให้มันเป็นภาพ Grayscale และย่อขนาดของมันให้เล็กลงเสียก่อน ซึ่งขนาดของภาพที่ถูกต้อง และภาพที่ไม่เกี่ยวข้องนั้น จะต้องมีขนาดเท่ากัน โดยในที่นี้เราจะย่อให้เหลือเพียง 200 x 200 pixels เท่านั้น โดยใช้ python code ด้านล่างนี้
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import urllib from urllib import urlopen import cv2 import numpy as np import os import time import glob cv2.namedWindow("Out",cv2.WINDOW_NORMAL) def store_raw_images(): # neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n03335030' neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n02692232' neg_image_urls = urlopen(neg_images_link).read() print neg_image_urls pic_num = 0 if not os.path.exists('neg'): os.makedirs('neg') for i in neg_image_urls.split('\n'): try: urllib.urlretrieve(i, "neg/"+str(pic_num)+".jpg") img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE) # should be larger than samples / pos pic (so we can place our image on it) resized_image = cv2.resize(img, (200, 200)) if resized_image is not None: cv2.imwrite("neg/"+str(pic_num)+".jpg",resized_image) print str(pic_num) + " - " + str(i) + "\n" pic_num += 1 except Exception as e: print(str(e)) store_raw_images() |
ในโค้ดนี้ จะมีหน้าที่ดาวน์โหลดรูป และแปลงรูปที่ดาวน์โหลดมาให้เป็นรูป Grayscale และย่อยขนาดให้เหลือ 200 x 200 pixels และนำไปเก็บไว้ยัง โฟลเดอร์ที่เราระบุไว้
นี่คือส่วนที่ระบุ urls และเปิดหน้าเพจที่ถูกระบุไว้
1 2 | neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n02692232' neg_image_urls = urlopen(neg_images_link).read() |
แสดงลิงค์ที่ได้จากการอ่านหน้าเพจนั้น
1 | print neg_image_urls |
ตั้งค่าเริ่มต้นของภาพ ในที่นี้ให้เป็น 0
1 | pic_num = 0 |
เช็คโฟลเดอร์ที่ต้องการเก็บว่ามีหรือไม่ ถ้าไม่มีให้สร้างโฟลเดอร์ไว้รอ
1 2 | if not os.path.exists('neg1'): os.makedirs('neg1') |
ดาวน์โหลดภาพจากลิงค์ที่ได้จากหน้าเพจนั้น และเก็บในโฟลเดอร์ neg ในนามสกุล jpg
1 | urllib.urlretrieve(i, "neg1/"+str(pic_num)+".jpg") |
เปิดไฟล์รูปที่โหลดไว้ขึ้นมาเพื่อแปลงรูปให้เป็น Grayscale และย่อขนาดรูปให้เหลือ 200 x 200 pixels
1 2 3 | img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE) # should be larger than samples / pos pic (so we can place our image on it) resized_image = cv2.resize(img, (200, 200)) |
เช็คว่ารูปที่โหลดมาทำการแปลงรูปสำเร็จหรือไม่ และเก็บไว้ในโฟลเดอร์ neg อีกครั้ง
และแสดงจำนวนลิงค์ที่อยู่ใน urls ทั้งหมด พร้อมกับจำนวนภาพล่าสุดที่นับไว้
1 2 | print str(pic_num) + " - " + str(i) + "\n" pic_num += 1 |
รันฟังก์ชัน store_raw_images() เพื่อเรียกใช้ฟังก์ชันที่เขียนไว้
1 | store_raw_images() |
ควรจะบันทึกชื่อรูปล่าสุดที่ได้ไว้นะครับ เพราะลำดับนั้น เราจะเอาไปตั้งให้กับไฟล์ที่ถูกต้องของเราอีกที
ทีนี้เมื่อเราได้รูปมาแล้ว ต่อมาเราต้องมาตรวจสอบความสมบูรณ์ของรูป ว่าใช้งานได้หรือไม่ มีรูปใดมีปัญหาในการโหลด หรือแสดงผลผิดไปหรือไม่ เนื่องจากลิงค์ที่ได้นั้นบางครั้ง รูปก็ไม่ได้พร้อมให้ใช้งานครับ เริ่มจากสำรวจรูปที่ผิดปกติในโฟลเดอร์ที่เราโหลดมาเก็บไว้ก่อนหน้านี้ครับ ภาพที่ผิดปกติจะมีลักษณะประมาณนี้ครับ
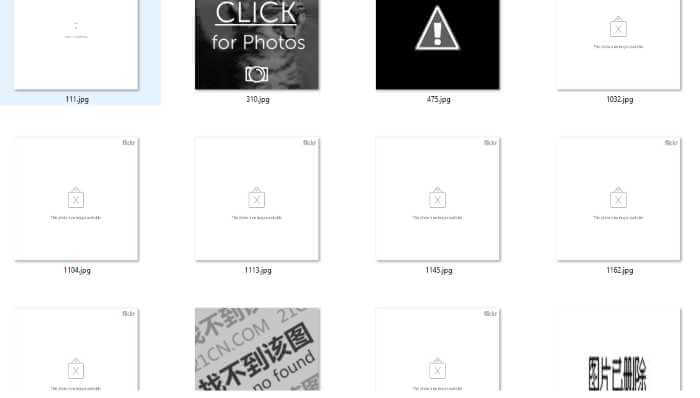
ตัวอย่างลักษณะของภาพที่เราไม่ต้องการ
ซึ่งหลายภาพคือภาพที่ไม่สามารถเปิดได้ บางภาพมีการระบุว่าหาไม่เจอ และอะไรอีกมากมาย ซึ่งเราไม่ต้องการครับโดยให้เราสร้างโฟลเดอร์ที่ชื่อ BadNeg ไว้ข้างนอกโฟลเดอร์ neg แล้วย้ายภาพตัวอย่างที่พบปัญหาไปไว้ในโฟลเดอร์นั้นแล้วเราจะใช้โค้ดชุดนี้ในการตรวจสอบครับ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | def find_uglies(): for ugly in glob.glob("BadNeg/*.jpg"): try : ugly_image_path = ugly ugly_jpeg = cv2.imread(ugly_image_path) if ugly_jpeg is not None: cv2.imshow('show_ugly',ugly_jpeg) cv2.waitKey(1) for img in glob.glob("neg/*.jpg"): try: img_image_path = img img_jpeg = cv2.imread(img_image_path) print str(img_image_path) + " from "+ str(len(ugly)) +" - " + str(ugly_image_path) + " from " + str(len(img)) if img_jpeg is not None: cv2.imshow('show_neg',img_jpeg) cv2.waitKey(1) print str(img_jpeg.shape) + " - " + str(ugly_jpeg.shape) if (ugly_jpeg.shape) == (img_jpeg.shape) and not(np.bitwise_xor(ugly_jpeg,img_jpeg).any()): print "***That is one ugly pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) else: print "***That is one connot open pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) except IOError as e: print "neg - " +str(e.value) else: print "***That is one connot open pic! Deleting!***" print str(ugly_image_path) os.remove(ugly_image_path) except IOError as e: print "BadNeg - " +str(e.value) find_uglies() |
เก็บชื่อรูปแต่ละรูปที่มีปัญหาซึ่งเราได้เลือกไว้ในโฟลเดอร์ BadNeg ไว้ในตัวแปร ugly
1 | for ugly in glob.glob("BadNeg/*.jpg"): |
อ่านภาพจากชื่อที่เก็บไว้
1 2 | ugly_image_path = ugly ugly_jpeg = cv2.imread(ugly_image_path) |
เช็คว่าภาพเปิดได้รึเปล่า ถ้าเปิดได้ให้แสดงภาพขึ้นมา
1 | cv2.imshow('show_ugly',ugly_jpeg) |
แต่ถ้ารูปตัวอย่างเปิดไม่ได้ก็ลบรูปตัวอย่างเช่นกัน
1 2 3 | print "***That is one connot open pic! Deleting!***" print str(ugly_image_path) os.remove(ugly_image_path) |
เก็บชื่อรูปแต่ละรูปในโฟลเดอร์ neg ไว้ในตัวแปล img
1 | for img in glob.glob("neg/*.jpg"): |
อ่านภาพจากที่อยู่ที่เก็บไว้
1 2 3 | img_image_path = img img_jpeg = cv2.imread(img_image_path) print str(img_image_path) + " from "+ str(len(ugly)) +" - " + str(ugly_image_path) + " from " + str(len(img)) |
ถ้าภาพที่อ่านไว้ สามารถเปิดได้ ให้แสดงภาพ
1 2 3 4 | if img_jpeg is not None: cv2.imshow('show_neg',img_jpeg) cv2.waitKey(1) print str(img_jpeg.shape) + " - " + str(ugly_jpeg.shape) |
เปรียบเทียบภาพระหว่างภาพตัวอย่าง กับภาพในโฟลเดอร์ที่เราต้องการคัดกรอง
ถ้าเหมือนกัน ให้ลบรูปในโฟลเดอร์ที่เราต้องการคัดกรองออก
1 2 3 4 | if (ugly_jpeg.shape) == (img_jpeg.shape) and not(np.bitwise_xor(ugly_jpeg,img_jpeg).any()): print "***That is one ugly pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) |
แต่ถ้าเปิดไม่ได้ ให้ลบรูปนั้นทันที
1 2 3 | print "***That is one connot open pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) |
รันฟังก์ชัน find_uglies() เพื่อเรียกใช้ฟังก์ชันที่เขียนไว้
1 | find_uglies() |
หลังจากทำส่วนนี้แล้ว จำนวนรูปจะลดลง แต่อาจจะยังไม่หมด เราจึงควรกลับเข้าไปเช็ค และทำซ้ำอีกครั้ง จนกว่าจะหมด
เมื่อจัดการเรื่องรูปในส่วนที่เป็นรูปไม่เกี่ยวข้องนี้เสร็จแล้ว เราจะได้ไฟล์รูปที่ไม่เกี่ยวข้องกับรูปที่เราสนใจทั้งหมดอยู่ในโฟลเดอร์ neg
และเราจะต้องทำแบบเดียวนี้อีกครั้งกับ urls ของรูปที่เราสนใจ โดยสำหรับรูปที่เราสนใจนั้น เราจะเก็บมันไว้ในโฟลเดอร์ pos โดยแก้ไขจาก Code ก่อนหน้านี้ ที่ใช้สำหรับรูปที่ไม่เกี่ยวข้อง โดยเปลี่ยนจาก neg เป็น pos แบบนี้
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | def store_raw_images(): neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n03335030' # neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n02692232' neg_image_urls = urlopen(neg_images_link).read() print neg_image_urls pic_num = #แก้เป็นไฟล์ถัดจากลำดับสุดท้ายของ neg if not os.path.exists('pos'): os.makedirs('pos') for i in neg_image_urls.split('\n'): try: urllib.urlretrieve(i, "pos/"+str(pic_num)+".jpg") img = cv2.imread("pos/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE) # should be larger than samples / pos pic (so we can place our image on it) resized_image = cv2.resize(img, (200, 200)) if resized_image is not None: cv2.imwrite("pos/"+str(pic_num)+".jpg",resized_image) print str(pic_num) + " - " + str(i) + "\n" pic_num += 1 except Exception as e: print(str(e)) |
เปลี่ยนลิงค์ไปยังรูปที่เราสนใจ
1 2 | neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n03335030' # neg_images_link = 'http://image-net.org/api/text/imagenet.synset.geturls?wnid=n02692232' |
เช็ค และสร้างโฟลเดอร์ pos สำหรับเก็บรูปที่เราสนใจ
1 2 | if not os.path.exists('pos'): os.makedirs('pos') |
เก็บไฟล์รูปที่เราสนใจไว้ในโฟลเดอร์ pos ดังนั้นเราจึงต้องเปลี่ยนจาก neg เป็น pos ให้หมด
1 2 3 4 5 6 7 8 9 10 11 12 13 | for i in neg_image_urls.split('\n'): try: urllib.urlretrieve(i, "pos/"+str(pic_num)+".jpg") img = cv2.imread("pos/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE) # should be larger than samples / pos pic (so we can place our image on it) resized_image = cv2.resize(img, (200, 200)) if resized_image is not None: cv2.imwrite("pos/"+str(pic_num)+".jpg",resized_image) print str(pic_num) + " - " + str(i) + "\n" pic_num += 1 except Exception as e: print(str(e)) |
จากนั้นให้จัดการไฟล์ที่ไม่สามารถเปิดได้ และไฟล์ที่ผิดปกติ สำหรับโฟลเดอร์ pos นี้ด้วย โดยแก้ชื่อโฟลเดอร์ให้เป็น pos เช่นกัน แต่ยังคงใช้โฟลเดอร์ BadNeg สำหรับเก็บไฟล์ตัวอย่างที่ผิดปกติเช่นเดิม
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | def find_uglies(): for ugly in glob.glob("BadNeg/*.jpg"): try : ugly_image_path = ugly ugly_jpeg = cv2.imread(ugly_image_path) if ugly_jpeg is not None: cv2.imshow('show_ugly',ugly_jpeg) cv2.waitKey(1) for img in glob.glob("pos/*.jpg"): try: img_image_path = img img_jpeg = cv2.imread(img_image_path) print str(img_image_path) + " from "+ str(len(ugly)) +" - " + str(ugly_image_path) + " from " + str(len(img)) if img_jpeg is not None: cv2.imshow('show_pos',img_jpeg) cv2.waitKey(1) print str(img_jpeg.shape) + " - " + str(ugly_jpeg.shape) if (ugly_jpeg.shape) == (img_jpeg.shape) and not(np.bitwise_xor(ugly_jpeg,img_jpeg).any()): print "***That is one ugly pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) else: print "***That is one connot open pic! Deleting!***" print str(img_image_path) os.remove(img_image_path) except IOError as e: print "pos - " +str(e.value) else: print "***That is one connot open pic! Deleting!***" print str(ugly_image_path) os.remove(ugly_image_path) except IOError as e: print "BadNeg - " +str(e.value) |
แก้ for img in glob.glob(“neg/*.jpg”): เป็น for img in glob.glob(“pos/*.jpg”):
แก้ print “neg – ” +str(e.value) เป็น print “pos – ” +str(e.value)
และลองรันแบบเดียวกันไฟล์ที่เราทำในโฟลเดอร์ neg เช่นเดียวกัน
ตอนนี้เราก็จะได้ไฟล์ครบถ้วนที่เราจะนำมาใช้แล้ว
ขั้นตอนต่อมาคือการทำไฟล์ให้อยู่ในรูปของข้อมูลเพื่อนำไปใช้งาน
เปิด terminal console เตรียมไฟล์ที่ใช้รวมภาพที่เราสนใจโดยใช้คำสั่ง
1 | $find ./pos -iname "*.jpg" > pos.txt |
และเตรียมไฟล์ที่ใช้รวมภาพที่ไม่เกี่ยวข้องกับสิ่งที่เราสนใจ โดยใช้คำสั่ง
1 | $find ./neg -iname "*.jpg" > neg.txt |
สรุป
ถึงตอนนี้ เราจะมีไฟล์อยู่ 2 ไฟล์คือ
pos.txt ที่ใช้เก็บที่อยู่รูปที่เราสนใจ
neg.txt ที่ใช้เก็บที่อยู่รูปที่ไม่เกี่ยวข้องกับรูปที่เราสนใจ
และโฟลเดอร์เก็บรูป 2 โฟลเดอร์คือ
pos ที่ใช้เก็บรูปที่เราสนใจ
neg ที่ใช้เก็บรูปที่ไม่เกี่ยวข้องกับรูปที่เราสนใจ
สร้างเวกเตอร์ไฟล์
ต่อมาเราต้องสร้างไฟล์เวกเตอร์ ( vec ) จากรูปทั้งหมดที่เรามี โดยใช้ opencv_createsamples ที่มีมาให้ใน opencv หลังจากที่เราได้ติดตั้งไปแล้ว โดยที่ผมใช้จะติดตั้งอยู่ในโฟลเดอร์ /usr/bin/opencv_createsamples แต่สำหรับบางท่านอาจจะแตกต่างจากนี้
สำหรับโปรแกรม opencv_createsamples นี้ จะสร้างไฟล์เวกเตอร์ สำหรับรูปที่เราสนใจ 1 รูป เทียบกับรูปที่ไม่เกี่ยวข้องกับสิ่งที่เราสนใจทุกรูป และเราจะได้ไฟล์นามสกุล vec ขึ้นมา 1 ไฟล์ แต่ในตอนนี้เรามีรูปที่เราสนใจอยู่หลายรูป ถ้าจะมาเรียกจากรูปที่เราสนใจทีละรูปคงจะใช้เวลานานมากแน่ๆ จึงมีคนเขียนสคริปส์ให้สามารถทำงานได้อัตโนมัติ โดยเรียกตามที่อยู่ในไฟล์ นั่นคือเหตุผลที่ทำให้เราสร้างไฟล์ txt ไว้ก่อนหน้านี้ครับ
นี่คือ โค้ด ที่ใช้ในการเรียก opencv_createsamp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | #!/usr/bin/perl use File::Basename; use strict; ########################################################################## # Create samples from an image applying distortions repeatedly # (create many many samples from many images applying distortions) # # perl createtrainsamples.pl <positives.dat> <negatives.dat> <vec_output_dir> # [<totalnum = 7000>] [<createsample_command_options = ./createsamples -w 20 -h 20...>] # ex) perl createtrainsamples.pl positives.dat negatives.dat samples # # Author: Naotoshi Seo # Date : 09/12/2008 Add <totalnum> and <createsample_command_options> options # Date : 06/02/2007 # Date : 03/12/2006 ######################################################################### my $cmd = 'usr/bin/opencv_createsamples -bgcolor 0 -bgthresh 0 -maxxangle 0 -maxyangle 0 maxzangle 0 -maxidev 40 '; my $totalnum = 7000; my $tmpfile = 'tmp'; if ($#ARGV < 2) { print "Usage: perl createtrainsamples.pl\n"; print " <positives_collection_filename>\n"; print " <negatives_collection_filename>\n"; print " <output_dirname>\n"; print " [<totalnum = " . $totalnum . ">]\n"; print " [<createsample_command_options = '" . $cmd . "'>]\n"; exit; } my $positive = $ARGV[0]; my $negative = $ARGV[1]; my $outputdir = $ARGV[2]; $totalnum = $ARGV[3] if ($#ARGV > 2); $cmd = $ARGV[4] if ($#ARGV > 3); open(POSITIVE, "< $positive"); my @positives = <POSITIVE>; close(POSITIVE); open(NEGATIVE, "< $negative"); my @negatives = <NEGATIVE>; close(NEGATIVE); # number of generated images from one image so that total will be $totalnum my $numfloor = int($totalnum / $#positives); my $numremain = $totalnum - $numfloor * $#positives; # Get the directory name of positives my $first = $positives[0]; my $last = $positives[$#positives]; while ($first ne $last) { $first = dirname($first); $last = dirname($last); if ( $first eq "" ) { last; } } my $imgdir = $first; my $imgdirlen = length($first); print "==========> image directory: " . $imgdir . "\n"; print "==========> image directory len: " . $imgdirlen . "\n"; for (my $k = 0; $k < $#positives; $k++ ) { #for (my $k = 0; $k < 1; $k++ ) { my $img = $positives[$k]; my $num = ($k < $numremain) ? $numfloor + 1 : $numfloor; # Pick up negative images randomly my @localnegatives = (); for (my $i = 0; $i < $num; $i++) { my $ind = int(rand($#negatives)); push(@localnegatives, $negatives[$ind]); } open(TMP, "> $tmpfile"); print TMP @localnegatives; close(TMP); #system("cat $tmpfile"); !chomp($img); my @tokens = split(/\s+/, $img); my $vec = $outputdir . substr($tokens[0], $imgdirlen) . ".vec" ; print "==========> splitted image: " . $tokens[0] . "\n"; print "==========> vec file: " . $vec . "\n"; print "$cmd -img $tokens[0] -bg $tmpfile -vec $vec -num $num" . "\n"; system("$cmd -img $tokens[0] -bg $tmpfile -vec $vec -num $num"); } unlink($tmpfile); |
หรือจะ clone ไฟล์นี้มาก็ได้ครับ https://github.com/mrnugget/opencv-haar-classifier-training หากโหลดไฟล์นี้มา createsamples.pl จะอยู่ในโฟลเดอร์ bin และท่านอาจจะแก้ไขตำแหน่งการเรียกใช้ opencv_createsamp ในบรรทัดที่ 17 ของโค้ดให้ถูกต้องครับ ท่านจึงจะสามารถเรียกใช้ได้ แนะนำว่านำไฟล์นี้ออกมาอยู่ในตำแหน่งเดียวกันกับไฟล์ pos.txt และ neg.txt จะทำให้ใช้งานได้ง่ายกว่านะครับ
โดย createsamples.pl จะเรียกใช้ opencv_createsamp ทุกๆไฟล์ใน pos.txt เทียบกับ neg.txt และสร้างไฟล์ vec ไว้ให้ในโฟลเดอร์ที่เราได้กำหนดไว้ดังนี้
$perl usr/bin/createsamples.pl pos.txt neg.txt samples 1200 "opencv_createsamples -bgcolor 0 -bgthresh 0 -maxxangle 1.1 -maxyangle 1.1 maxzangle 0.5 -maxidev 10 -w 20 -h 20"
จากคำสั่งข้างต้นนั้นระบุว่า เราใช้ไฟล์ pos.txt สำหรับรูปที่เราสนใจ neg.txt สำหรับรูปที่ไม่เกี่ยวข้องกับสิ่งที่เราสนใจ เก็บไฟล์ vec ไว้ในโฟลเดอร์ samples ซึ่งหลังจากรันแล้ว เราสามารถเข้าไปดูได้ จำนวนรูปที่จะใช้งานมีทั้งหมด 1200 รูป ( pos มี 240 รูป และ neg มี 987 รูป รวมแล้ว 1227 รูป แต่ใช้เพียง 1200 รูป )
-bgcolor ตั้งค่าสีของรูปที่ไม่เกี่ยวข้องกับสิ่งที่เราสนใจ ค่าปกติเป็น 0 คือเป็นภาพ grayscale
-bgthresh จะทำงานร่วมกับ -bgcolor โดย pixel ที่มีสีอยู่ระหว่าง -bgcolor +/- -bgthresh จะถูกทำให้โปร่งใส (transparent) ปกติเป็น 0
-maxangle ต่างๆคือ มุมการหมุนในหน่วยเรเดียน
-maxidev คือค่าความเบี่ยงเบนของความหนาแน่นสูงสุดของรูปที่เราสนใจ
-w, -h คือกำหนดขนาด output ในหน่วยของ pixels
เมื่อเรารันไฟล์ createsamples.pl ได้ถูกต้องแล้ว จะได้รายงานผลดังรูป
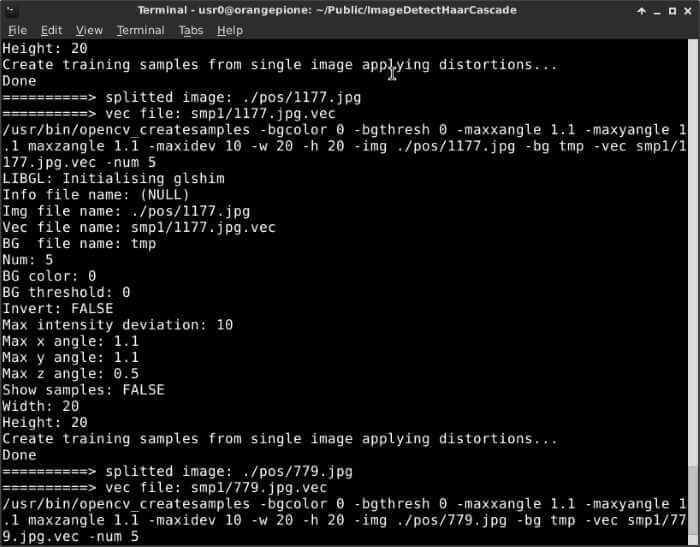
ภาพตัวอย่าง รายงานการทำงานจากการทำงานของ createtrainsamples.pl
และในโฟลเดอร์ samples จะมีไฟล์นามสกุล vec อยู่
เมื่อเราได้ไฟล์ vec แล้ว เราจะต้องทำการรวมเวกเตอร์ไฟล์ทั้งหมดให้เป็นไฟล์เดียวกันเสียก่อน เพราะเราต้องการไฟล์ cascade เพียง 1 ไฟล์เท่านั้น เราสามารถรวมไฟล์ได้โดยใช้สคริปส์ไฟล์นี้
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 | """ File: mergevec.py Author: [email protected] Date: 6/13/2014 File Description: This file contains a function that merges .vec files called "merge_vec_files". I made it as a replacement for mergevec.cpp (created by Naotoshi Seo. See: http://note.sonots.com/SciSoftware/haartraining/mergevec.cpp.html) in order to avoid recompiling openCV with mergevec.cpp. To use the function: (1) Place all .vec files to be merged in a single directory (vec_directory). (2) Navigate to this file in your CLI (terminal or cmd) and type "python mergevec.py -v your_vec_directory -o your_output_filename". The first argument (-v) is the name of the directory containing the .vec files The second argument (-o) is the name of the output file To test the output of the function: (1) Install openCV. (2) Navigate to the output file in your CLI (terminal or cmd). (2) Type "opencv_createsamples -w img_width -h img_height -vec output_filename". This should show the .vec files in sequence. """ import sys import glob import struct import argparse import traceback def exception_response(e): exc_type, exc_value, exc_traceback = sys.exc_info() lines = traceback.format_exception(exc_type, exc_value, exc_traceback) for line in lines: print(line) def get_args(): parser = argparse.ArgumentParser() parser.add_argument('-v', dest='vec_directory') parser.add_argument('-o', dest='output_filename') args = parser.parse_args() return (args.vec_directory, args.output_filename) def merge_vec_files(vec_directory, output_vec_file): """ Iterates throught the .vec files in a directory and combines them. (1) Iterates through files getting a count of the total images in the .vec files (2) checks that the image sizes in all files are the same The format of a .vec file is: 4 bytes denoting number of total images (int) 4 bytes denoting size of images (int) 2 bytes denoting min value (short) 2 bytes denoting max value (short) ex: 6400 0000 4605 0000 0000 0000 hex 6400 0000 4605 0000 0000 0000 # images size of h * w min max dec 100 1350 0 0 :type vec_directory: string :param vec_directory: Name of the directory containing .vec files to be combined. Do not end with slash. Ex: '/Users/username/Documents/vec_files' :type output_vec_file: string :param output_vec_file: Name of aggregate .vec file for output. Ex: '/Users/username/Documents/aggregate_vec_file.vec' """ # Check that the .vec directory does not end in '/' and if it does, remove it. if vec_directory.endswith('/'): vec_directory = vec_directory[:-1] # Get .vec files files = glob.glob('{0}/*.vec'.format(vec_directory)) # Check to make sure there are .vec files in the directory if len(files) <= 0: print('Vec files to be mereged could not be found from directory: {0}'.format(vec_directory)) sys.exit(1) # Check to make sure there are more than one .vec files if len(files) == 1: print('Only 1 vec file was found in directory: {0}. Cannot merge a single file.'.format(vec_directory)) sys.exit(1) # Get the value for the first image size prev_image_size = 0 try: with open(files[0], 'rb') as vecfile: content = ''.join(str(line) for line in vecfile.readlines()) val = struct.unpack('<iihh', content[:12]) prev_image_size = val[1] except IOError as e: print('An IO error occured while processing the file: {0}'.format(f)) exception_response(e) # Get the total number of images total_num_images = 0 for f in files: try: with open(f, 'rb') as vecfile: content = ''.join(str(line) for line in vecfile.readlines()) val = struct.unpack('<iihh', content[:12]) num_images = val[0] image_size = val[1] if image_size != prev_image_size: err_msg = """The image sizes in the .vec files differ. These values must be the same. \n The image size of file {0}: {1}\n The image size of previous files: {0}""".format(f, image_size, prev_image_size) sys.exit(err_msg) total_num_images += num_images except IOError as e: print('An IO error occured while processing the file: {0}'.format(f)) exception_response(e) # Iterate through the .vec files, writing their data (not the header) to the output file # '<iihh' means 'little endian, int, int, short, short' header = struct.pack('<iihh', total_num_images, image_size, 0, 0) try: with open(output_vec_file, 'wb') as outputfile: outputfile.write(header) for f in files: with open(f, 'rb') as vecfile: content = ''.join(str(line) for line in vecfile.readlines()) data = content[12:] outputfile.write(data) except Exception as e: exception_response(e) if __name__ == '__main__': vec_directory, output_filename = get_args() if not vec_directory: sys.exit('mergvec requires a directory of vec files. Call mergevec.py with -v /your_vec_directory') if not output_filename: sys.exit('mergevec requires an output filename. Call mergevec.py with -o your_output_filename') merge_vec_files(vec_directory, output_filename) |
เราสามารถรันไฟล์ mergevec.py เพื่อรวมไฟล์ vec ในโฟลเดอร์ที่เราสร้างไว้ ให้กลายเป็นไฟล์เดียวด้วยคำสั่ง
1 | $python mergevec.py -v samples -o samples.vec |
เราก็จะได้ไฟล์ samples.vec ที่เกิดจากการรวมไฟล์เวกเตอร์ในโฟลเดอร์ samples แล้ว
สรุปว่าในตอนนี้เรามีไฟล์เวกเตอร์ ของรูปที่เราสนใจ และไฟล์ที่อยู่ของรูปที่ไม่เกี่ยวข้องกับสิ่งที่เราไม่สนใจแล้ว
สุดท้ายก็คือการเอาไฟล์เวกเตอร์ของรูปที่เราสนใจ กับไฟล์ที่อยู่ของรูปที่ไม่เกี่ยวข้อง ไปสอนเพื่อให้ได้ xml ไฟล์ของรูปที่เราสนใจเพื่อนำไปใช้กับรูปอื่นๆต่อไป
แต่โปรแกรมที่ใช้เทรนนี้มีอยู่ 2 ตัวคือ opencv_haartraining และ opencv_traincascade ซึ่งให้ไฟล์ xml เช่นกัน แต่เป็นคนละมาตรฐาน โดย opencv_haartraining ยังจะคงใช้ในมาตรฐานเก่า และโปรแกรมอื่นๆก็ยังรองรับมาตรฐานนี้
แต่ opencv_traincascade จะเป็นมาตรฐานที่ใหม่กว่า opencv สามารถใช้มาตรฐานนี้ได้ และใช้เวลาในการสร้าง xml ไฟล์น้อยกว่า
ดังนั้นเราจึงเลือกใช้ opencv_traincascade แต่เนื่องจากการทำงานนี้จะกินเวลาที่ยาวนานมาก… อาจจะถึงข้ามวันกันได้เลยทีเดียว ( เคยลองรันไปสามวันเลย ) ดังนั้นเราจึงควรให้มันรันในระดับ Background และ monitor การทำงานผ่าน htop ( โปรแกรมดู task และการทำงาน บน linux ) จะดีกว่า โดยใช้คำสั่ง nohup และปิดท้ายด้วย &
ดังนี้
$nohup /usr/bin/opencv_traincascade -data data -vec samples.vec -bg neg.txt -numPos 230 -numNeg 950 -numStage 15 -w 20 -h 20 -precalcValBufSize 64 -precalcIdxBufSize 64 &
-data data คือระบุให้เก็บไฟล์ xml ไว้ในโฟลเดอร์นี้
-vec samples.vec ใช้ไฟล์เวกเตอร์ไฟล์นี้
-bg neg.txt ใช้รูปที่ไม่เกี่ยวข้องตามลิสต์นี้
-numPos 230 จำนวนรูปของสิ่งที่เราสนใจ ที่ใช้ในการคำนวณ
-numNeg 950 จำนวนของรูปที่ไม่เกี่ยวข้องกับสิ่งที่เราสนใจ ที่ใช้ในการคำนวน
-numStage 15 ระดับสเตจในการคำนวณ ยิ่งมากยิ่งละเอียด แต่ก็จะยิ่งนานมากเป็นทวีคูณ เพราะต้องคำนวณมากขึ้นเป็นจำนวนเท่า (Big O)
-w 20 -h 20 ขนาดภาพที่ใช้ในการคำนวณ แบบเดียวกับที่ใช้ในการทำเวกเตอร์ไฟล์
-precalcValBufSize 64 -precalcIdxBufSize 64 กำหนดขนาดของบัฟเฟอร์ซึ่งเมื่อรวมกันแล้วไม่ควรมากกว่าจำนวนแรมที่มีเหลือให้ใช้ ในกรณีนี้รันบน Orange Pi One ที่มีแรมเพียง 512MB และเหลือใช้จริงราวๆ 200MB นิดๆ เลยกำหนดเท่านี้และเปิดไว้นานๆๆๆๆๆๆๆๆๆ ครับ
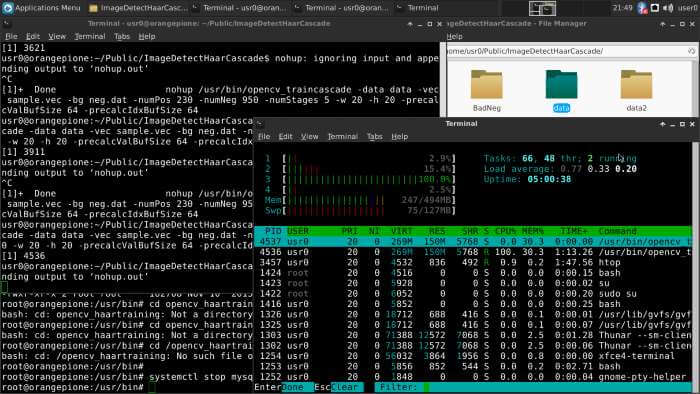
จากนั้นก็รอ…ครับ เราจะสังเกตว่าจะมี Process ID ที่ 4536 ที่โปรแกรมแจ้งเลข PID ให้กับเรา ทำงานอยู่ จากหน้าต่างของ htop
ตลอดเวลาการทำงานเราสามารถเข้าไปดูรายงานการทำงานได้ที่ไฟล์ nohup.out และดูไฟล์ที่ถูกสร้างได้ในโฟลเดอร์ data ครับ และเมื่อระบบทำงานเสร็จแล้ว เราจะได้ไฟล์ cascade.xml ในโฟลเดอร์ data ก็ถือว่าเรียบร้อยครับ
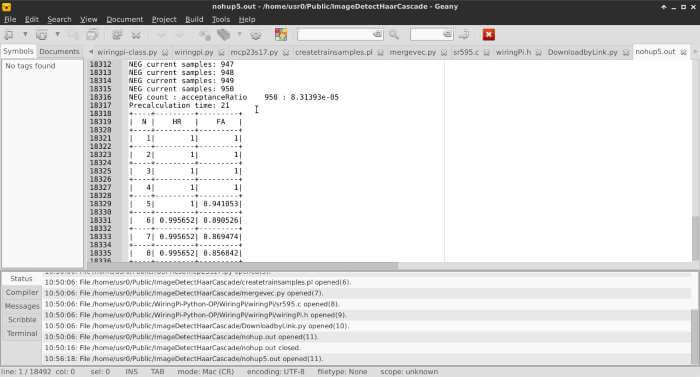
ตัวอย่าง ข้อมูลใน nohup.out
ข้อมูลใน nohup.out จะบอกค่าพารามิเตอร์ต่างๆ ซึ่งมีผลต่อประสิทธิภาพการทำงาน และความแม่นยำของไฟล์ cascade ที่เราจะได้ในแต่ละสเตจครับ
เมื่อระบบทำงานเสร็จ ผมเลือกที่จะก๊อปปี้ไฟล์ cascade.xml จากโฟลเดอร์ data ออกมาแล้วเปลี่ยนชื่อเป็น Aircascade15.xml เพื่อระบุว่าเป็นไฟล์สำหรับตรวจ Aircraft ที่ผลิตจากสเตจจำนวน 15 สเตจ จากนั้นเราก็สามารถนำไฟล์ที่ได้มาทดลองได้ครับ – ผมได้แชร์ไฟล์ที่ได้กระบวนการนี้ไว้ครับ สามารถดาวน์โหลดมาลองกันได้ก่อนครับ
https://drive.google.com/open?id=0B_9dScmDNMaCUE9DQTRkUkdrRWc
ทดลองใช้งาน
เราจะสร้างไฟล์ python ขึ้นมา โดยให้ทดลองกับการจับภาพเครื่องบินในไฟล์วิดีโอ โดยใช้ xml ที่เราสร้างขึ้นครับ
โดยผมเลือกดาวน์โหลดไฟล์วิดีโอ Airshow ที่มั่นใจว่ามีเครื่องบินแน่ๆ มาลองนะครับ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #opens up a webcam feed so you can then test your classifer in real time #using detectMultiScale import numpy import cv2 def detect(img): cascade = cv2.CascadeClassifier("Aircascade15.xml") rects = cascade.detectMultiScale(img, 1.3, 4, cv2.cv.CV_HAAR_SCALE_IMAGE, (50,50)) if len(rects) == 0: return [], img rects[:, 2:] += rects[:, :2] return rects, img def box(rects, img): for x1, y1, x2, y2 in rects: cv2.rectangle(img, (x1, y1), (x2, y2), (127, 255, 0), 2) #cv2.imwrite('one.jpg', img); cap = cv2.VideoCapture("RIAT_2014_RAF_Red_Arrow.mp4") cap.set(3,400) cap.set(4,300) while(True): ret, img = cap.read() rects, img = detect(img) box(rects, img) cv2.imshow("frame", img) if(cv2.waitKey(1) & 0xFF == ord('q')): break |
ระบุเลือกไฟล์ที่จะใช้ในการตรวจจับ และปรับค่าสเกลในการเปรียบเทียบ โดยยิ่งสเกลละเอียดก็จะยิ่งใช้เวลานาน และอาจจะทำให้ไม่สามารถระบุวัตถุที่มีขนาดใหญ่ได้
1 2 | cascade = cv2.CascadeClassifier("Aircascade15.xml") rects = cascade.detectMultiScale(img, 1.3, 4, cv2.cv.CV_HAAR_SCALE_IMAGE, (50,50)) |
ตีกรอบรอบวัตถุที่ตรวจับได้ โดยค่าที่ใช้จะเป็น ตำแหน่ง x1, y1 ของภาพ และขนาดกว้าง , สูง x2, y2 ของวัตถุในภาพ
1 2 3 | def box(rects, img): for x1, y1, x2, y2 in rects: cv2.rectangle(img, (x1, y1), (x2, y2), (127, 255, 0), 2) |
ตั้งขนาดภาพ และเลือกไฟล์วิดีโอที่จะตรวจสอบ ถ้าหากเปิดจากกล้อง ให้เปลี่ยนเป็น
cap = cv2.VideoCapture(0) ครับ
1 2 3 | cap = cv2.VideoCapture("RIAT_2014_RAF_Red_Arrow.mp4") cap.set(3,400) cap.set(4,300) |
อ่านภาพทีละเฟรม และเอาแต่ละเฟรมมาตรวจหา และวาดกรอบ แล้วแสดงทั้งหมดขึ้นบนจอ
1 2 3 4 | ret, img = cap.read() rects, img = detect(img) box(rects, img) cv2.imshow("frame", img) |
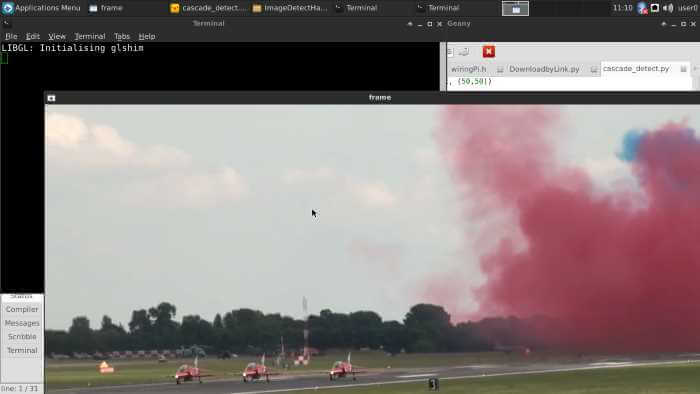
ช่วงแรกจากทางด้านหน้า ตรวจไม่เจออะไร
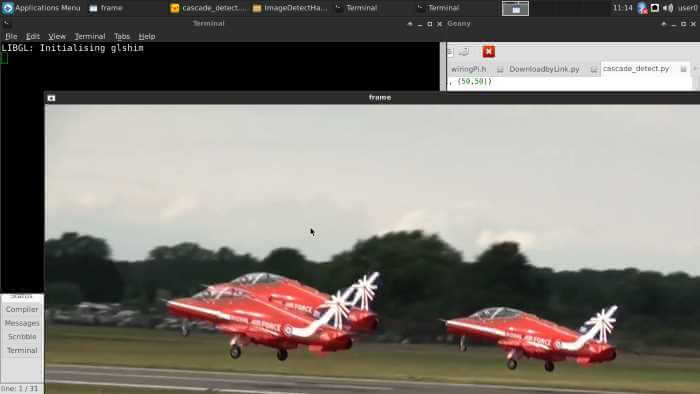
ช่วงถัดมาจากด้านข้าง ยังคงตรวจไม่เจอ
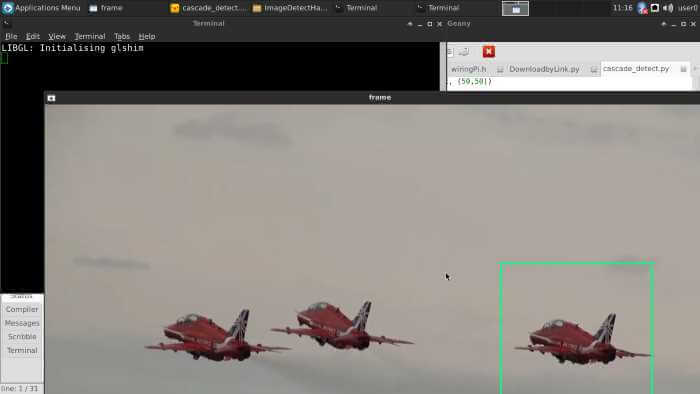
จากข้างหลัง กลับตรวจเจอ
อาจจะเป็นไปได้ว่ารูปตัวอย่างมีรูปจากมุมนี้ค่อนข้างเยอะ
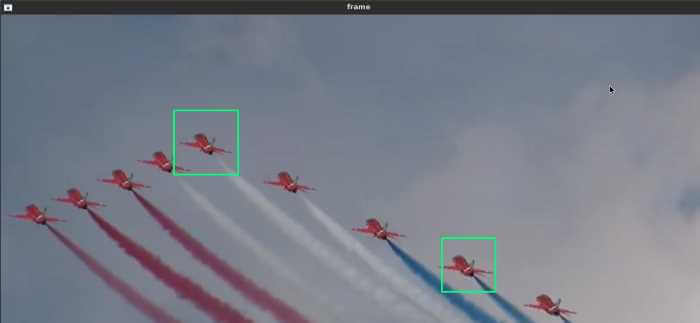

ภาพจากด้านบน และอีกมุม ตรวจจับได้ค่อนข้างดี และในหลายๆมุมนั้นตรวจจับได้เป็นส่วนใหญ่เลยครับ
สรุปผล
จากกระบวนการอันยาวเหยียดข้างบนนี้ เราสามารถสร้างไฟล์ Cascade ที่เอาไว้ใช้กับฟังค์ชั่น Haar Cascade เพื่อตรวจจับสิ่งที่เราสนใจจากภาพถ่ายหรือวิดีโอได้
สามารถนำไปประยุกต์ใช้ในงานได้หลากหลายครับ
ไม่ว่าจะเป็นงานที่ต้องใช้การคัดเลือกด้วยสายตา ( Vision Inspect )
งานที่ต้องการ การติดตามวัตถุบางอย่าง
งานด้านการเกษตร ที่ใช้นับจำนวนผลผลิต หรือติดตามการเติบโต และวัดขนาดของผลผลิต
งานสำหรับนับคนในพื้นที่หนึ่ง
งานตรวจหาคน จากกลุ่มคน ก็มาสามารถนำไปประยุคต์ใช้ได้เช่นกัน
และยังสามารถขยายไปยังการพัฒนาให้ระบบสามารถเรียนรู้วัตถุ ได้จากภาพในเฟรมของวิดีโอ
เพื่อการะบุที่แม่นยำ และเจาะจงมากขึ้นได้ครับ
หวังว่าวิธีการนี้คงจะมีประโยชน์สำหรับทุกๆท่านนะครับ
อ้างอิง
https://pythonprogramming.net/haar-cascade-object-detection-python-opencv-tutorial/
http://coding-robin.de/2013/07/22/train-your-own-opencv-haar-classifier.html
http://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
http://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html
https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework
http://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html
An Extended Set of Haar-like Features for Rapid Object Detection
https://pdfs.semanticscholar.org/72e0/8cf12730135c5ccd7234036e04536218b6c1.pdf
Rapid Object Detection using a Boosted Cascade of Simple Features
https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
https://en.wikipedia.org/wiki/Cascading_classifiers
https://github.com/mrnugget/opencv-haar-classifier-training
https://github.com/mrnugget/opencv-haar-classifier-training/blob/master/bin/createsamples.pl