Machine Learning in Action : เริ่มต้นด้วยเกมเล็กๆอย่าง Tic Tac Toe
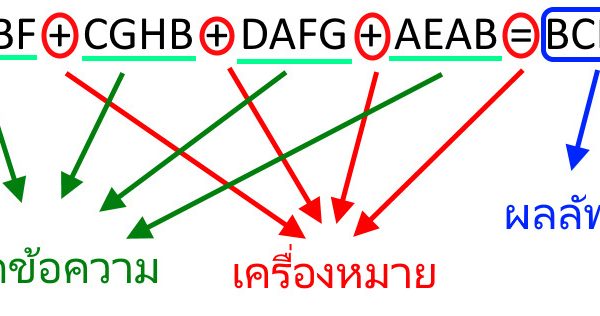
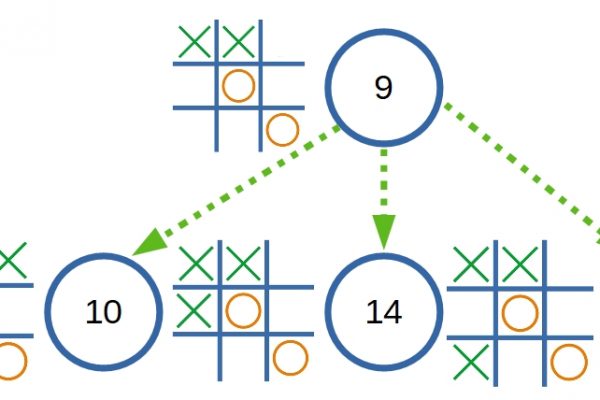
มีไอเดียอยากลองทำเกมง่ายๆ ที่สามารถเรียนรู้ หรือพัฒนาตนเองได้ด้วยประสบการณ์ที่ตัวมันได้พบเจอมา ซึ่งมันก็มีหลายเทคนิคที่มีใช้กันอยู่ และที่เห็นว่าน่าสนใจก็เป็น Q-Learning และ Minimax ทั้งสองเทคนิคล้วนแล้วแต่เป็น State–Action–Reward–State คือ เริ่มต้นคิดจาก State ปัจจุบัน เพื่อหา Action และประเมินผลเป็น Reward จาก State อีกที ซึ่งเหมาะสมมากที่จะนำมาใช้ในระบบเกม ส่วนเกมที่สนใจจะนำมาทดลองนั้น ก็เป็นเกมง่ายๆ อย่างเกม Tic Tac Toe ที่มีรูปแบบไม่เยอะมากนัก กฎกติกาไม่ซับซ้อน และเป็นการแข่งขันกันของสองผู้เล่น ทำให้ระบบสามารถเรียนรู้ หรือเลียนแบบ วิธีการเล่นของฝั่งตรงข้ามได้โดยง่าย ผ่าน State ที่ได้บันทึกไว้ก่อนหน้านี้เท่านั้นเอง ข้อเสียของวิธีการใช้ State แบบนี้คือ รูปแบบในการเล่นมักจะถูกจำกัดอยู่เฉพาะจากประสบการณ์ที่ผ่านมาเท่านั้น แม้จะเป็นการเลือกวิธีการเล่นที่ดีที่สุด แต่ก็จะดีที่สุดเท่าที่รู้อยู่เท่านั้น ดังนั้นถ้าประสบการณ์ของมันเต็มไปด้วยวิธีการที่ไม่มีคุณภาพ หรือไร้ประสิทธิภาพแล้ว